各位牢玩家,你是否想过《赛博朋克 2077》中实时渲染的霓虹光影,与 ChatGPT 生成诗文的智能背后,竟藏着相同的硬件秘密?本文将为你拆解 GPU 驱动 AI 的核心原理,并手把手教你用开源神器 LM Studio 打造本地 AI 实验室。
一、显卡:从游戏引擎到 AI 引擎的华丽转身
1.1 为何 GPU 是 AI 的「超算核心」?
在《原神》中,你的 RTX 显卡每秒要完成763 亿晶体管的图形计算;而在 AI 领域,同样的硬件正在以300-1000 倍于 CPU 的速度处理神经网络。这得益于 GPU 的三大特性:
- 万核并行:高端 GPU 拥有16384 个 CUDA 核心,如同万名小学生同步解方程,轻松应对矩阵运算(如 Y=WX+b)这类 AI 核心算法
- 带宽革命:GDDR6X 显存提供1TB/s 带宽,相当于每秒传输 50 部 4K 电影,远超 CPU 的 50-100GB/s
- 专用加速器:NVIDIA 的 Tensor Core 可在一个时钟周期完成64 组 4x4 矩阵运算,专为深度学习优化
当你在中体验光线追踪时,GPU 正在执行与 AI 训练相似的并行计算——区别在于前者渲染多边形,后者处理参数矩阵。
1.2 CPU 与 GPU 的「教授与小学生」哲学
| 维度 | CPU(全能教授) | GPU(万名小学生) |
|---|---|---|
| 核心数量 | 4-24 个复杂核心 | 数千个精简核心 |
| 任务类型 | 复杂逻辑判断(如物理引擎) | 海量简单运算(如像素着色) |
| 典型场景 | 操作系统调度、代码编译 | 游戏渲染、AI 模型推理 |
以训练 ChatGPT 为例:单个 CPU 需288 年,而万核 GPU 集群仅需数天——这正是 OpenAI 选择1 万个 GPU开发 ChatGPT 的原因。
二、LM Studio:本地 AI 实验室搭建指南
2.1 工具优势:游戏 Mod 式体验
- 零代码部署:如同加载 MC 材质包,支持 GGUF 格式模型导入(需自行下载模型文件)
- 隐私守护者:完全离线运行,敏感数据永不外传(适合处理学习资料/个人创作)
- 硬件解放:支持 NVIDIA/AMD 显卡加速,甚至能用核显运行 7B 小模型
2.2 Try it out!(以 RTX 3060 显卡为例)
Step 1:硬件体检
- 最低配置:16GB 内存 + 6GB 显存(《艾尔登法环》推荐配置)
- 理想配置:24GB 显存(可运行 70B 大模型,如《巫师 3》4K 材质包需求)
Step 2:模型获取与镜像加速
方法一:手动下载
- 访问 HuggingFace 官网【或 hf-mirror.com 镜像站】下载 GGUF 格式模型(如 Llama3-8B)
- 在 LM Studio 中点击【”…”→”Models”→”Open models folder”】将模型文件放入对应目录
方法二:在 LM Studio 中自动安装
- 进入 Chat 页面,点击顶部的搜索按钮,进行搜索并下载新的模型。
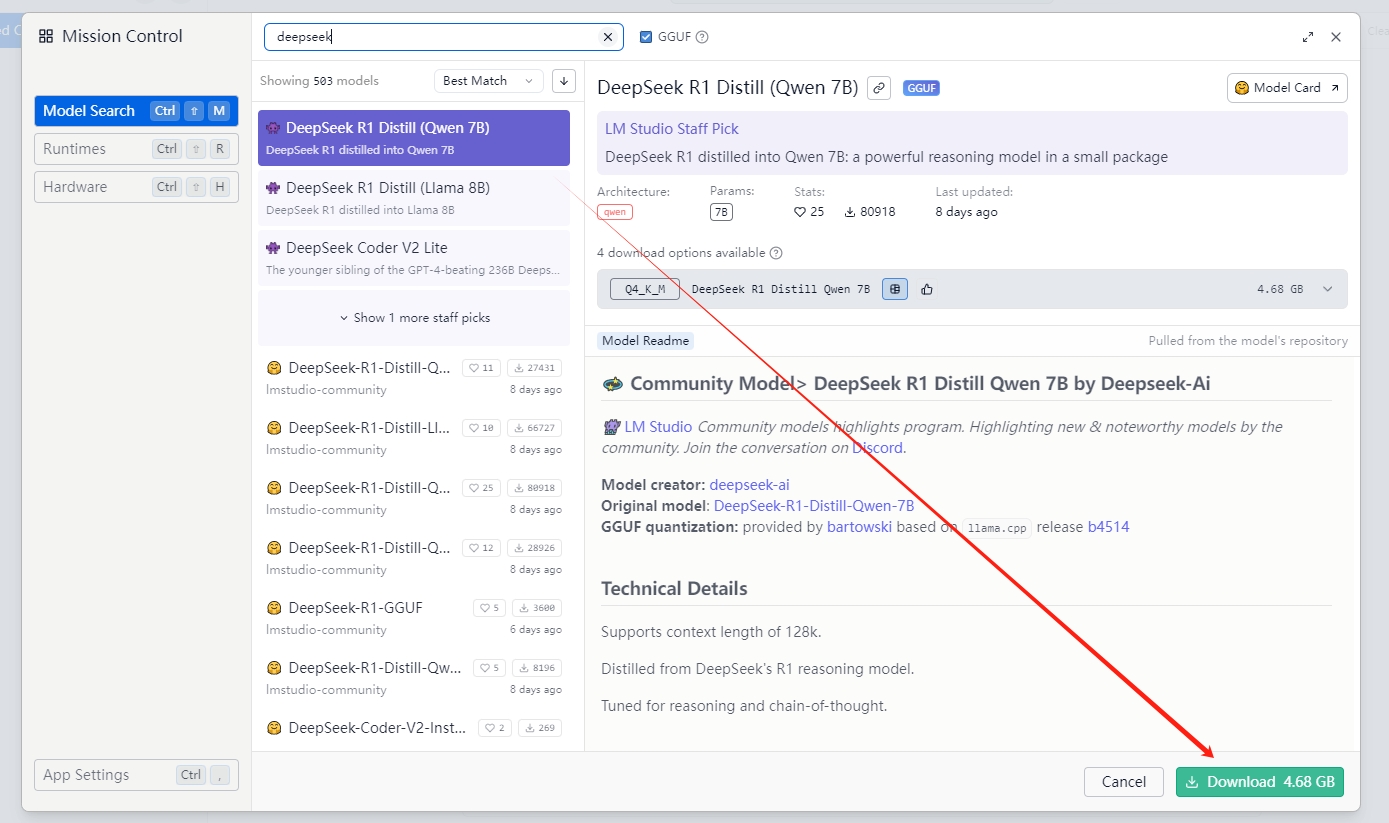
- 点击“Search more…”进入到检索界面,检索的信息中按照下图形式选中并点击下载即可:
Step 3:模型选型
| 模型规格 | 显存占用 | 适用场景 | 类比游戏画质 |
|---|---|---|---|
| Llama3-8B | 6GB | 写小作文/改代码 | 《CS2》中等特效 |
| DeepSeek-7B | 5GB | 解数学题/逻辑推理 | 《DOTA2》狂暴模式 |
| Mixtral-8x7B | 24GB | 翻译外文/处理长文档 | 《赛博朋克》光追拉满 |
也可以通过以下表格开参考:
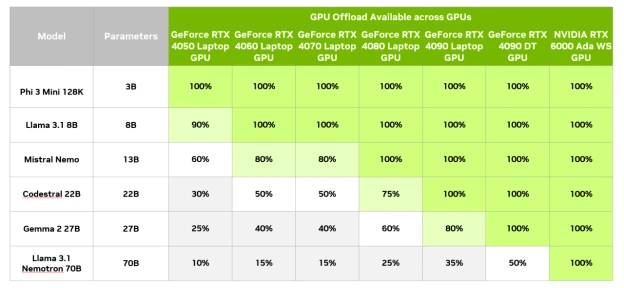
不同显卡的常见模型选择
Step 4:GPU 加速设置
- 加载模型后进入
Advanced面板 - 开启
GPU Offload并滑动GPU Layers(建议 RTX 3060 设为 20 层) - 监控显存占用(任务管理器→性能→GPU),确保不超过 90%
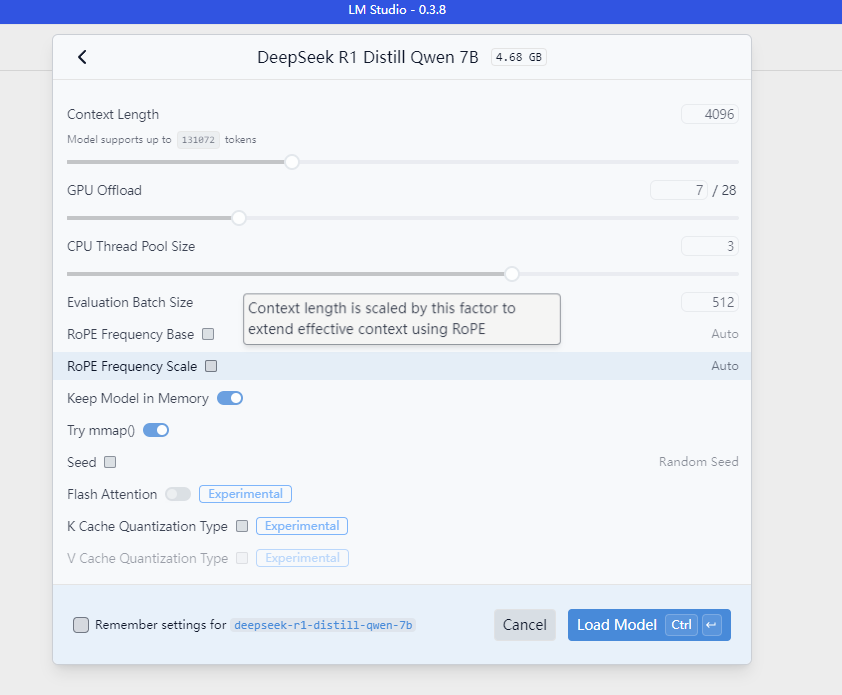
模型参数
三、未来已来:你的显卡正在解锁生产力新形态
当你的 RTX 3060 在《赛博朋克 2077》中渲染夜之城的霓虹时,它已悄然成为你桌面的 AI 工作站——这揭示了现代硬件的终极潜力:同一套 GPU 架构既能驱动虚拟世界,也能构建智能工具。
现在开始实践:下次等待《GTA6》加载时,不妨在 LM Studio 里让显卡生成一段开放世界剧情——这才是现代游戏硬件的完整价值闭环。
参考链接:LM Studio 非官方中文文档